.svg)
.svg)
.svg)
.svg)
.svg)






.avif)

.svg)
.svg)
.svg)




Anatomy of a Compliant Voice Agent for Life Sciences

Inside the loop of compliant, real-time conversational AI
When people think about AI agents, they often picture a simple chatbot. A user types a prompt, waits briefly, and receives a response. But enterprise voice agents, especially in high-stakes fields like life sciences, operate very differently. They are real-time systems designed to sustain continuous, compliant conversations while handling natural speech and meeting strict medical and regulatory expectations.
This post breaks down the anatomy of a voice agent. We look at the pipeline that enables trusted conversations with HCPs, field teams, and patients, and the challenges that come with building voice systems for enterprise use.
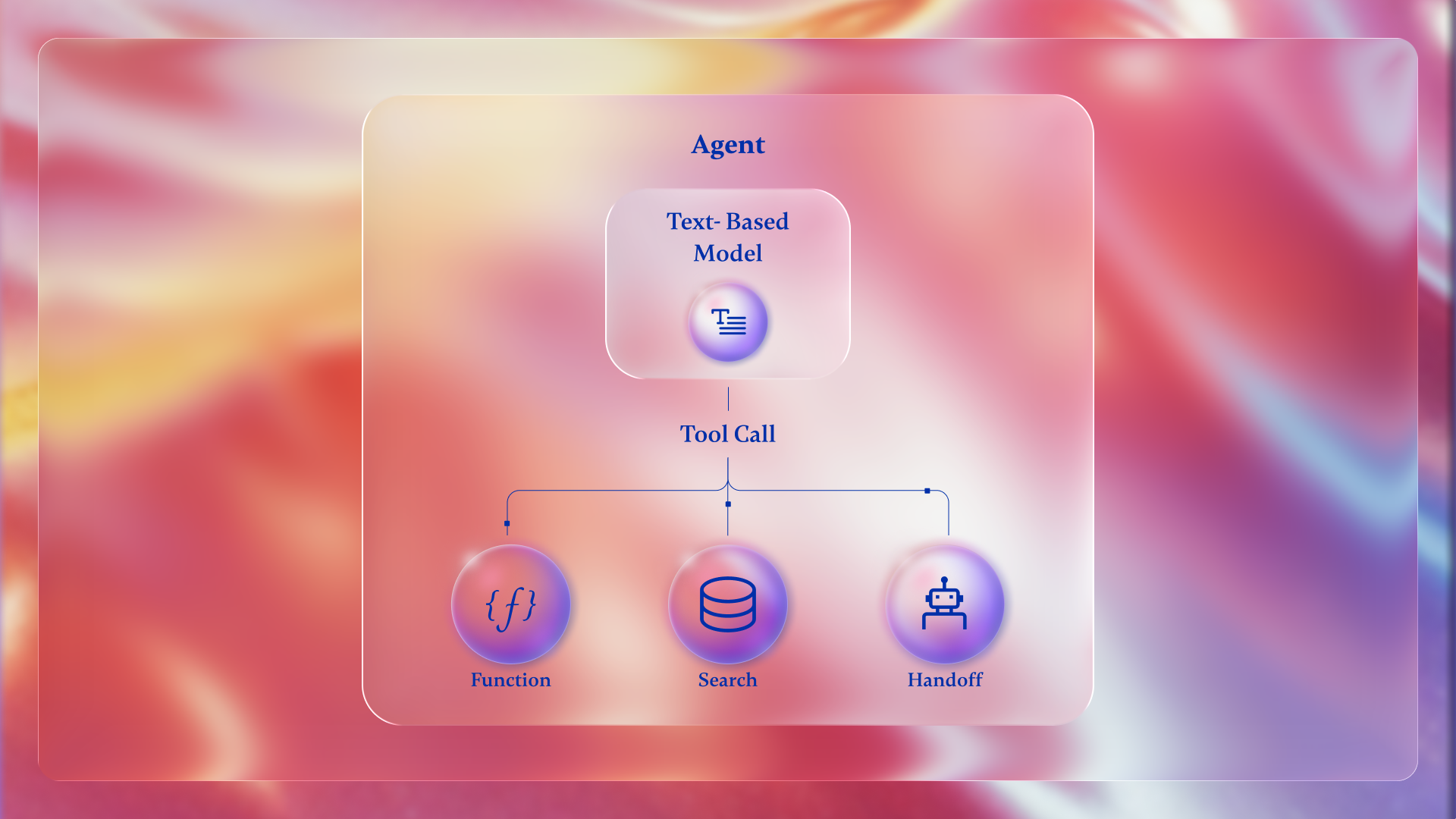
The Core Loop
A voice agent does not behave like a traditional web application where a request is followed by a response. Instead, it runs as a closed feedback loop that operates continuously. To feel natural, this loop typically targets end-to-end latency under 800 milliseconds.
The lifecycle of a single conversational turn includes six stages:
- Audio Capture: Raw audio is captured from the user’s device as a real-time stream. Data packets must be buffered and processed immediately, often containing complex medical terminology
- Translation (Speech-to-Text): The audio stream is sent to a transcription model. Transcription happens continuously, producing partial text while the user is still speaking. In life sciences, the model must accurately recognize drug names and clinical terms
- Clinical Reasoning: Transcripts are passed to a large language model supported by a clinical reasoning engine. This layer synthesizes information using approved brand content and medical literature while maintaining conversational context
- Tool Execution: Based on the request, the agent invokes specialized tools. For dosage questions, it uses clinical calculators. For field teams, it can generate pre-call briefs or structure post-call notes immediately after an interaction
- Synthesis (Text-to-Speech): The agent’s response is converted back into audio. This process is streamed, allowing audio to begin before the full response is complete. Accurate pronunciation of medical terms is essential for safety and trust
- Audio Output: The synthesized audio is streamed back to the user, delivering clear and empathetic communication
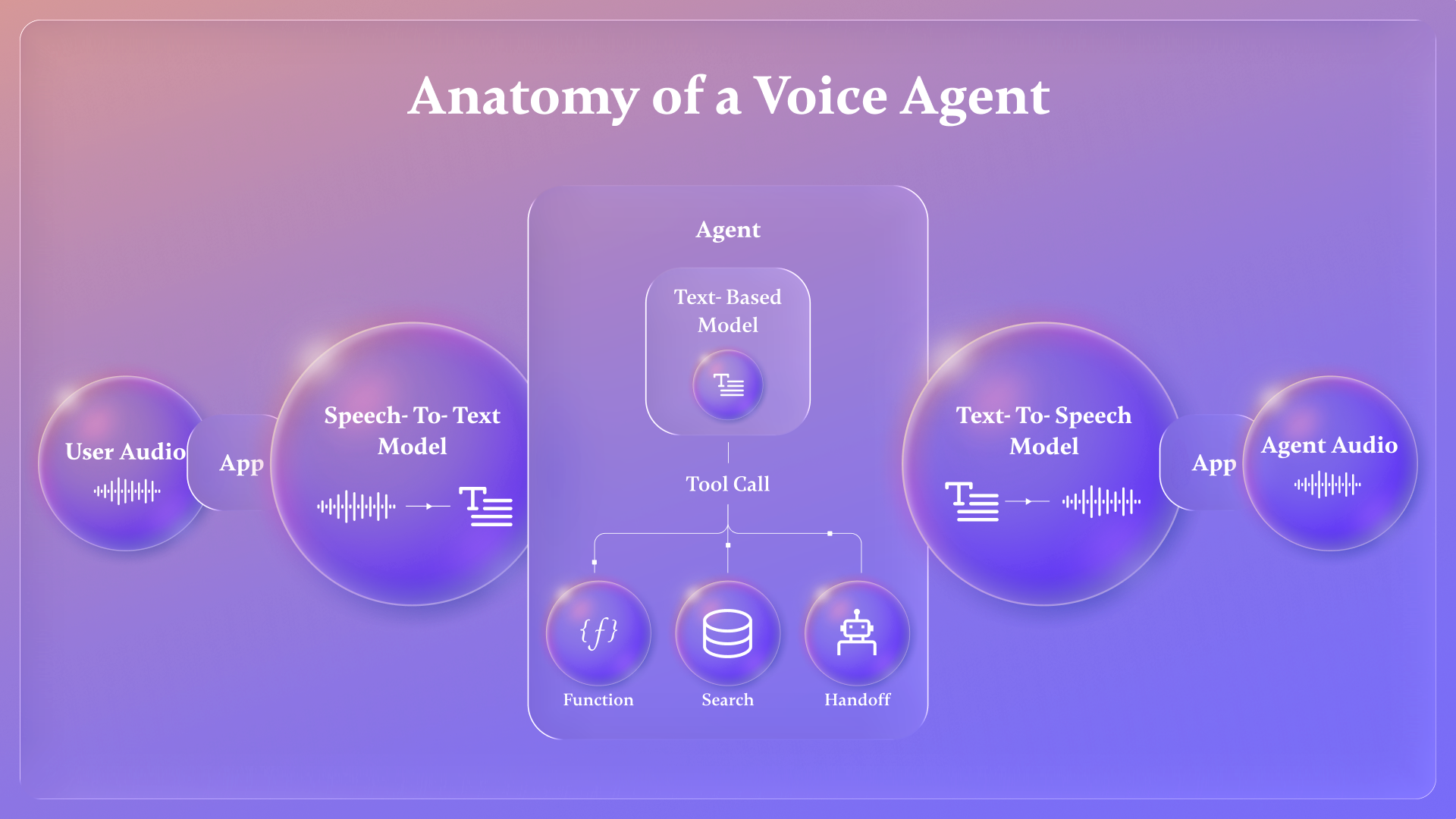
Engineering Challenges at Scale
While the diagram suggests a clean sequence, real systems are more complex. Much of the work happens in the transitions between stages.
Endpoint Detection
Determining when a user has finished speaking is one of the hardest problems in voice AI. Responding too quickly risks interruption. Waiting too long creates uncomfortable silence. The system relies on voice activity detection and semantic cues to tell the difference between a pause and a completed thought.
Handling Interruptions
Interruptions are common in real conversations, particularly in clinical settings. A voice agent must support barge-in. When the user starts speaking mid-response, the agent stops audio playback, clears its buffer, and shifts focus to the new input while updating context.
Safety and Governance
Life sciences leave no margin for error. Guardrails operate directly in the loop. Tool calls must be authorized, and every response must comply with medical, legal, and regulatory standards, as well as pharmacovigilance requirements. A governance layer surrounds the model to prevent unsafe actions and unsupported claims.
Speculative Execution
Meeting sub-second latency often requires acting before the user finishes speaking. With speculative execution, the system triggers a model response based on partial transcripts when intent appears clear. If the user continues, the response is discarded and regenerated. This approach reduces perceived delay without compromising accuracy.
Conclusion
Building a voice agent for life sciences requires coordination across real-time systems, clinical reasoning, and compliance controls.
At Synthio Labs, we address these challenges with infrastructure designed specifically for pharmaceutical use. Our platform provides the real-time voice backbone, clinical reasoning capabilities, and governance required to support compliant conversations at scale. This allows life sciences teams to focus on patient outcomes and HCP engagement while relying on a proven foundation for real-time AI.