.svg)
.svg)
.svg)
.svg)
.svg)






.avif)

.svg)
.svg)
.svg)




The Compression Fault: Modern Pharma Stack Has a Data Quality Problem


Every day, thousands of field representatives engage in highly technical, nuanced conversations with healthcare professionals. These interactions contain the most valuable proprietary data an organization owns: immediate needs, emerging treatment barriers, and sentiment regarding new clinical data.
Yet, the vast majority of this signal is discarded the moment the meeting ends.
Due to legacy compliance concerns and rigid database schemas, organizations force field teams to summarize complex dialogues into predefined drop-down selections. The richness of the human conversation is compressed into a binary "Call Completed" metric.
We are building a different architecture. We treat the field interaction not as a row to be logged in a database, but as an unstructured data stream to be computed.
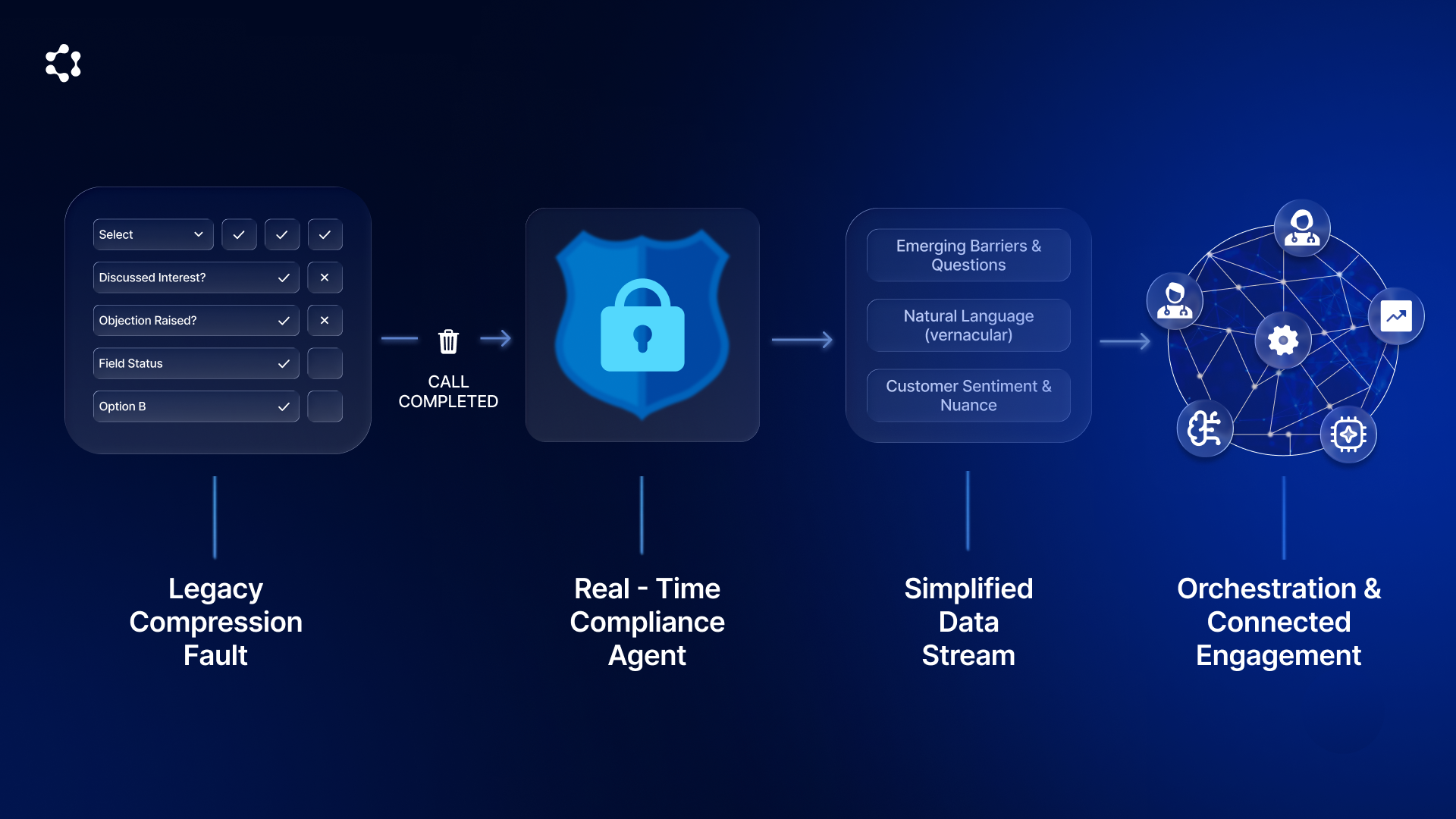
The Compression Fault
The industry reliance on structured data entry assumes that a finite set of drop-down values can capture the infinite variability of a medical discussion. This is an engineering fallacy.
When a field team member is forced to fit a conversation into a checkbox, connectivity and nuance are lost. A drop-down can record that a product was discussed, but it cannot capture the physician's hesitation about a specific mechanism of action or an unsolicited question about an off-label topic.
This data compression limits the efficacy of downstream investments. High-value orchestration engines and AI models require deep, contextual inputs to function effectively. Relying on generic meeting notes joined with third-party prescription data does nothing to advance these initiatives.
We focused on solving the input bottleneck. The only way to capture the "true intent" of the customer is to permit the field force to express themselves in their own vernacular.
Constructing the Compliance Guardrail
The barrier to free text has never been technical capability; it has been regulatory risk. The fear that a user might inadvertently document an unapproved claim or proprietary patient information drives organizations to default to restrictive data capture policies.
We solved this by moving compliance from a post-hoc audit process to a real-time compute layer.
Our architecture deploys a "Free Text Agent" that acts as an intermediary between the user and the system of record. This agent scans the input stream in real-time before submission.
Unlike passive text fields, the agent is active. It identifies potential non-compliant entries—such as unapproved therapeutic claims or competitor pricing—and offers in-the-moment coaching to the user. This allows the removal of sensitive content without blocking the capture of the broader commercial narrative.
This shift allows us to unlock the full context of the discussion within the organization's compliance guardrails.
From Storage to Orchestration
The move from structured drop-downs to compliant free text changes the fundamental nature of the dataset.
We are no longer simply recording activity, we are building a foundation for connected engagement. Rich primary engagement data becomes the differentiator that strengthens relationship management.
When deep contextual data is captured effectively, it connects the dots across functions. A distinct insight captured by a sales rep can immediately inform the next action for a medical liaison or a marketing lead, ensuring that every interaction informs the next.
This is the requirements baseline for the next generation of commercial software. Orchestration models and pre-call agents cannot operate on empty signals. They need the texture of the real world. By engineering a system that embraces the messiness of human language while enforcing the strictness of regulatory rules, we turn the field force into the ultimate source of intelligence.