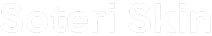.svg)
.svg)
.svg)
.svg)
.svg)






.avif)

.svg)
.svg)
.svg)




Why We Evaluate Voice Agents in Voice


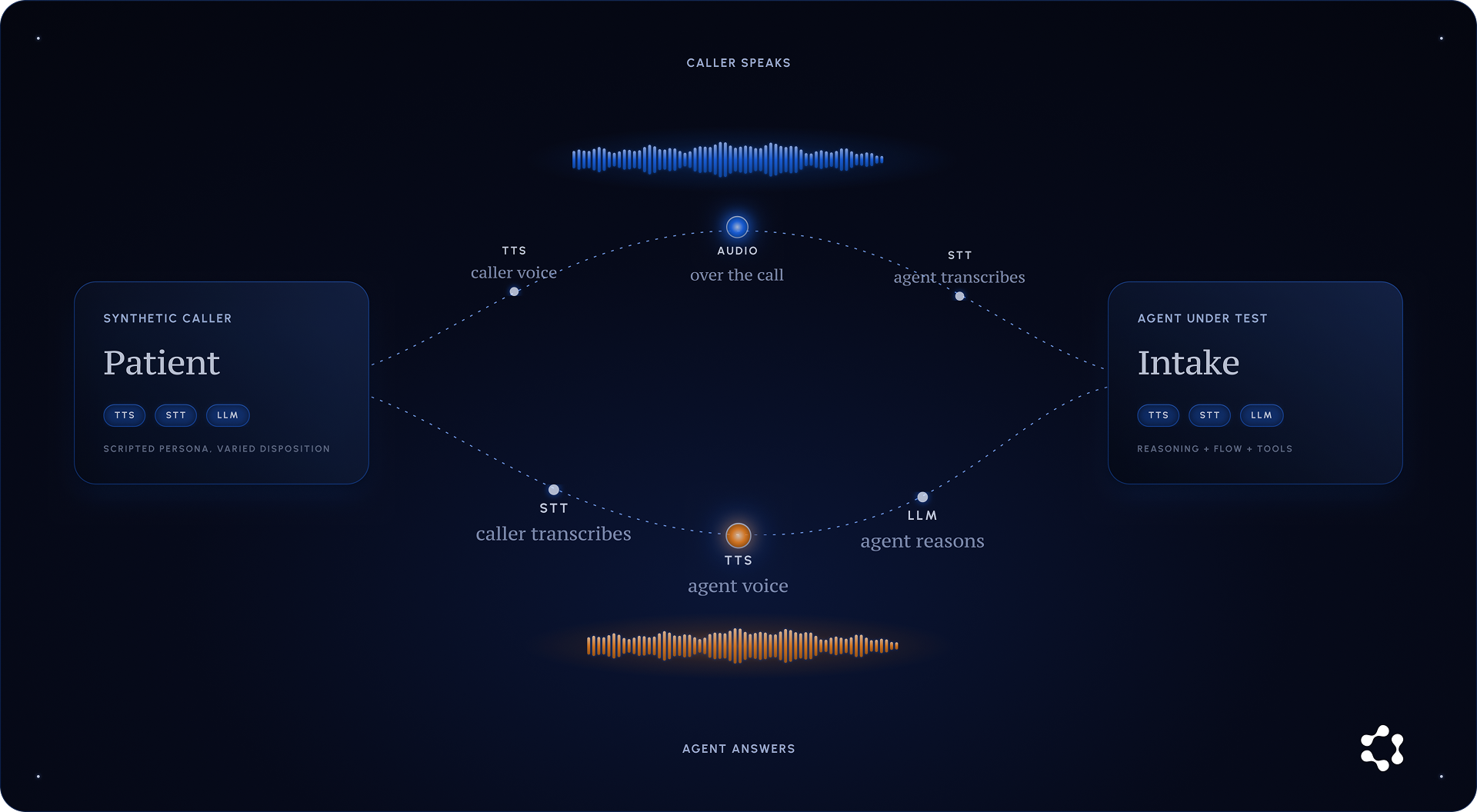
The right way to evaluate a voice agent is to have another voice agent talk to it.
We run our agents against a synthetic one in a live voice conversation. Both sides go through TTS, STT, and an LLM. Two AI agents talk to each other over the same infrastructure that real users connect through.
Most teams test voice agents on text. It's faster to set up and easier to score. It misses timing, interruptions, and the failures that only appear in audio. Text evals tell you whether the agent reasons correctly. Voice evals tell you whether it works in the real world.
Generic testing tools also evaluate the wrong things for our domain. Responsiveness and CSAT don't tell you whether the agent captured the right clinical signals or followed the compliance flow. A tool that doesn't understand your domain can't score whether the agent handled it correctly.
How It Works
We write scenarios that define who the synthetic agent is and what they know. The user doesn't volunteer information. They respond to questions, and their behavior varies across runs: patient or rushed, clear or mumbled. We force the agent to ask the right things in the right order across different caller dispositions.
Domain-specific terms are approximated in speech: drug names, clinical terms, etc. In a text eval, you'd write the correct spelling and move on. In voice, the agent's STT has to handle what it heard. If it can't, it either asks for clarification or logs the wrong thing. Both are not ideal. Neither shows up in a text eval.

The eval criteria are domain-specific too. The agent needs to capture the right information, follow the required conversational flow, and handle edge cases correctly. Scoring that requires knowing what the agent is supposed to do, not just whether it was polite.
The Loop
We run this like CI for voice. Every agent change goes through the scenario suite before it ships. A change either passes or it breaks something specific you can point to.
When a run fails, you know what failed, where in the conversation, and what the expected behaviour was. You fix the agent, run it again, score again.
One run caught something we hadn't anticipated. The agent passed the required question in every text eval. In voice, the caller started speaking before the agent finished asking. The agent's TTS got interrupted mid-sentence. The caller said "yeah, sure," an early affirmative before they heard the full question. The LLM treated it as an answer and moved on. The required field was logged as collected. It wasn't.
The reasoning was fine. The failure sat between the truncated agent turn and the LLM treating an early affirmative as a valid response to a question that was never fully asked. In a text eval that sequence can't happen: you pass a complete question, you get a complete answer. The transcript looked clean too. A question, then an answer. You'd catch it only by running the eval in voice modality where the interruption is real.
Before this, improving an agent meant listening to calls and guessing at what to change. Now there's a specific failure, in a specific moment, with evidence.
What This Means for Building Voice Agents
Most voice agent development runs on subjective feedback and slow iteration.
Evaluating in voice modality, with domain-specific criteria, closes that loop. You know what passed, what failed, and why. By the time an agent ships, it has run thousands of voice conversations against realistic scenarios.
You iterate on evidence.